APPENDIX: Data Tidying
In Taskstream 1 of Open Music Europe, we plan to retrospectively harmonise the data from the Slovak cultural statistical KULT surveys.
](png/tidy-1.png)
Figure 13.6: Following three rules makes a dataset tidy: variables are in columns, observations are in rows, and values are in cells. From R For Data Science - 12. Tidy Data
We use the KULT summary documents to re-create the necessary metadata of the KULT microdata files and to create checkpoints. These PDF files contain the Slovak variable labels for each survey’s module and columns and the sum of numeric values, which will be used as checksums when we read the raw data into R.

It is possible to work with pdf files in R with the tabulizer package, which can create a fully reproducible workflow, but in our case, it would be a prolonged process because we need to work with many PDF files. Instead, we converted the PDF files to a Word document and copied the tabular information into Excel. In tabulizer, you would have to figure out the coordinates of the table in the partly graphical PDF file and then read it into R. When you work between Word and Excel, you do this visually with a mouse.
13.3.1 Translations
Because I do not speak Slovak, I used DeepL to understand what happened in the PDF files. We will not need this step in our project because we work with native Slovak speakers. Eventually, we will create bilingual labelling, but we will do it differently because of our need for consistency. Adding the translation offers a way to understand the tidy data (table) concept.
13.3.2 From Word to Excel
In our case, the information in the PDF file is stored as text and numbers and not as a scanned picture; therefore, we do not need OCR software to guess what the image of letters and numbers means. We have a usable Word file and can select the tables carefully, ensuring all headings are chosen.
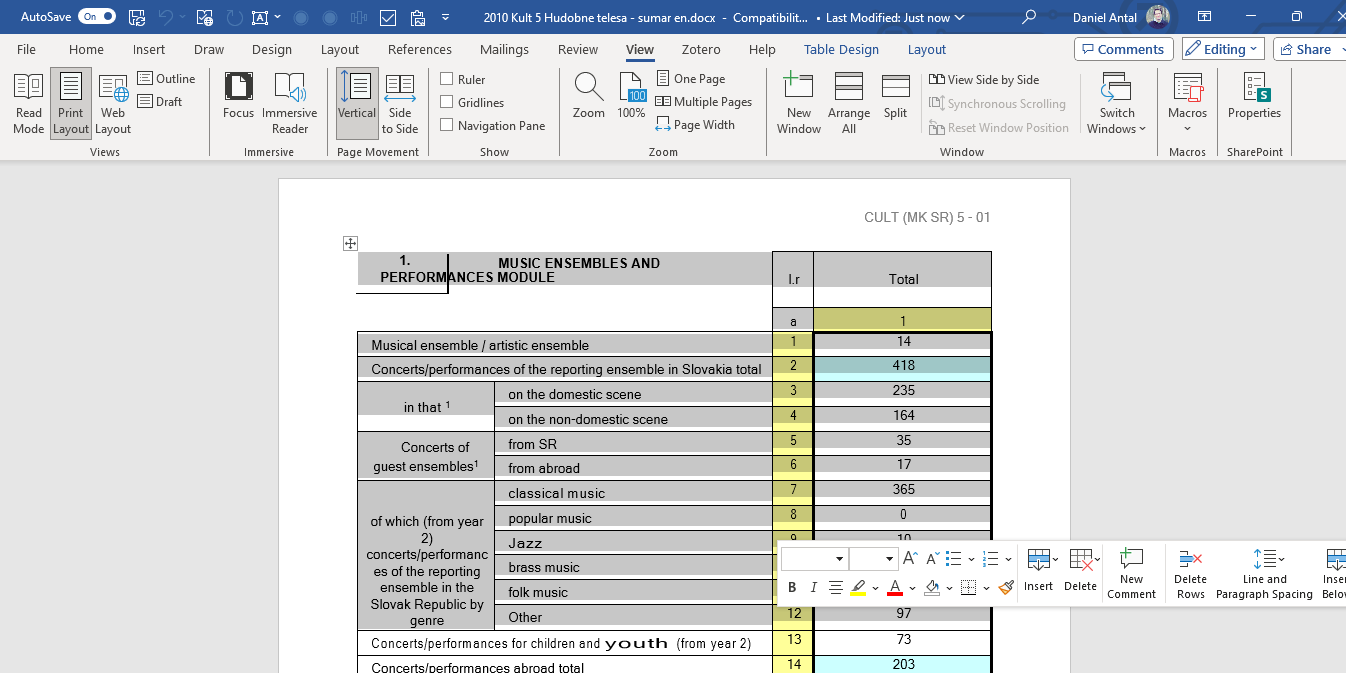
Many conversion utilities can convert a PDF file into an Excel spreadsheet file. We work in Word because this way, we can avoid the same problem that we did not work with the tabulirzer R package: the converter utility does not for sure what a margin is and what is already part of a table. In Excel, your columns will not be aligned, rendering the conversion of a larger table useless. (I repeat the same procedure with the English language translations, as you will see below.)
If you open the example Excel file, you will see examples of already well-copied data. You can use them to copy and paste a header to the top of a new sheet, in this case, the sheet made in the KULT-5 Excel file for the 2010 data.
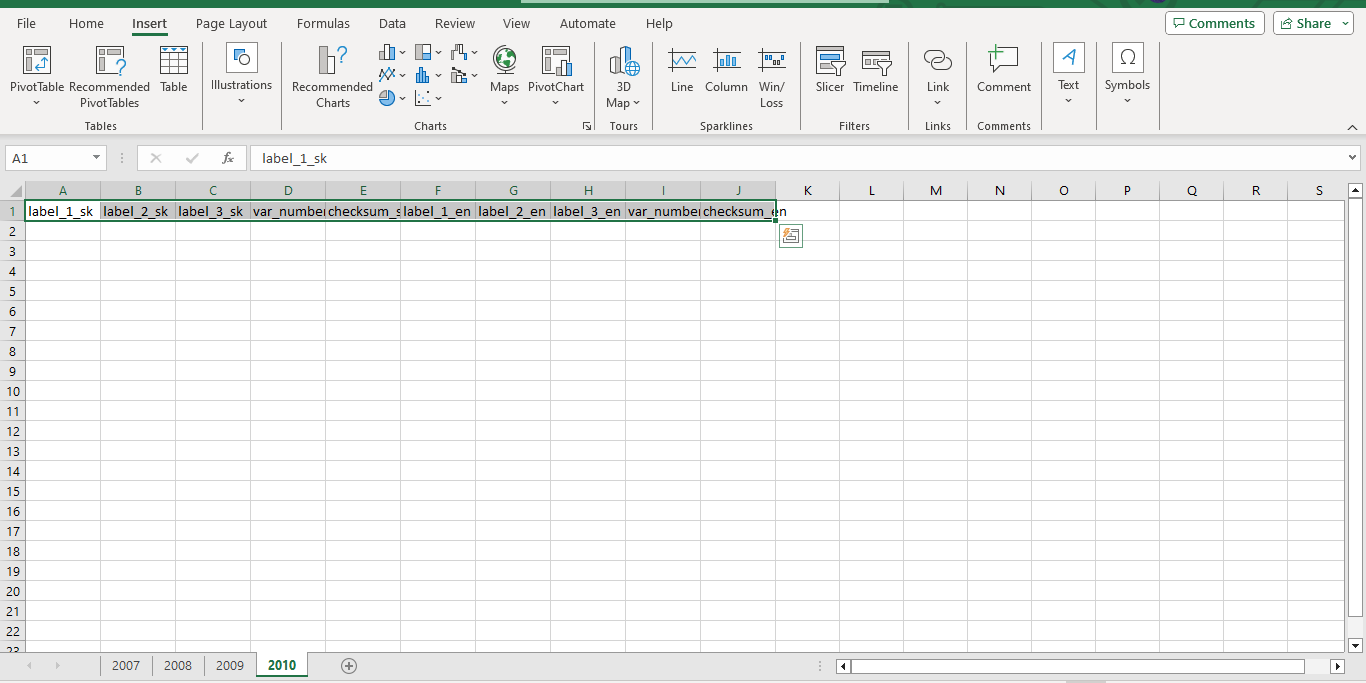
I used straightforward column names: label_1_sk for the first Slovak language labels, label_2_sk for the second, and label_3_sk for the third. In the KULT PDF for 2007 the table was broken into three columns (because of the merged summary columns), but later, it was more, so I had to add a label_4_sk. There were two critical columns: a numbering, which serves as a guide to the columns of the microdata CSV file, and the actual sum of numeric information reported by the statistical subjects.
For example, Concerts/performances of the reporting ensemble in Slovakia total stitched with on the domestic scene corresponds to the 3rd column in Module 1 of the KULT-05 survey in 2010. The total of this statistic is 235. I call the number three var_number_sk and the total value a checksum_sk because it will be used to check if we read in the microdata correctly. The _sk suffix is used to record that this information is coming from the Slovak version of the Word file; in the unlikely case that you made a copying mistake, it is better to know where to search for the correspondence with the authoritative files. For labelling, the _sk and _en suffixes serve a natural purpose; I do not want to mix up Slovak and English-translated label elements.
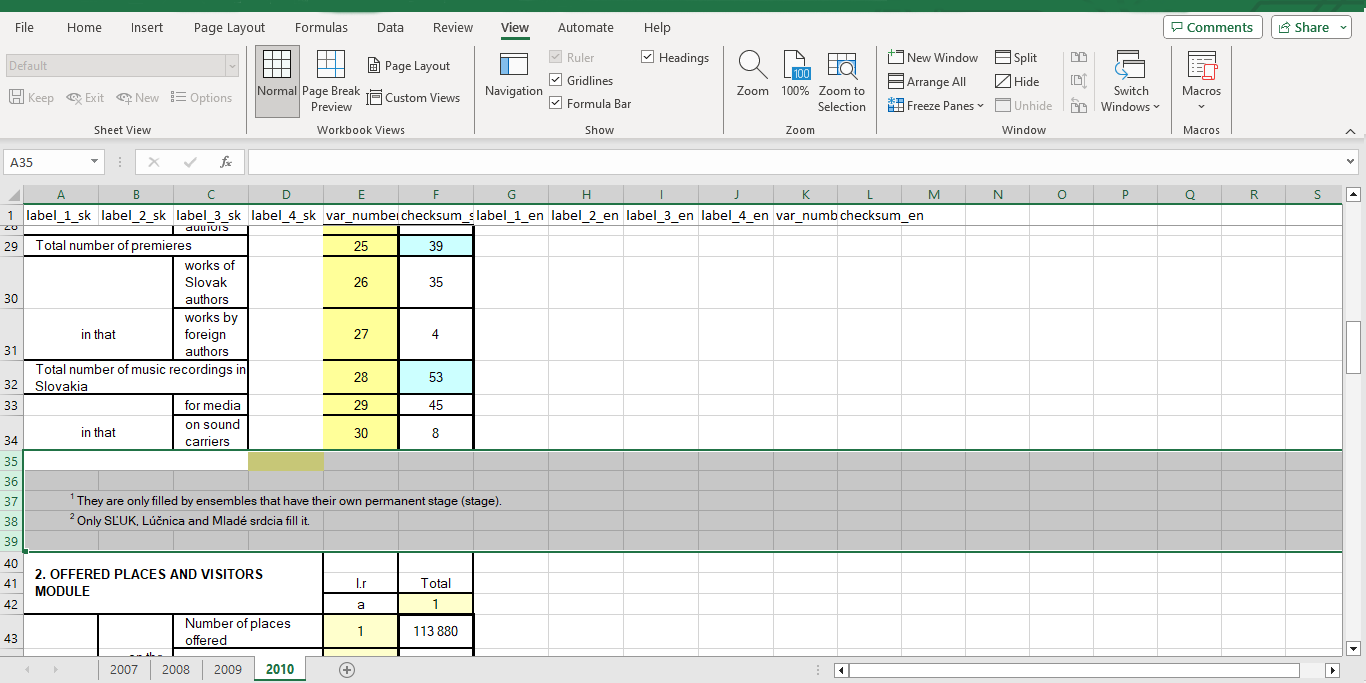
In a tidy data table, every observation is a row, and every variable is a column. In this case, the observation corresponds to a variable (a column in the microdata_file_); our KULT-05 summary PDF is observing what can be found in the original microdata. If you work with translations, you must ensure that Concerts/performances of the reporting ensemble in Slovakia total are in the same line in all languages because they observe the meaning of the same variable in the microdata.
The variables, or the columns, must be well-aligned. For example, the var_number_sk must always fall into the same column. Because the table is adjusted from the top left-hand corner, I drag the columns from left to right whenever something does not align. Because the lower Module 2 table has more columns than the upper Module 1, I dragged the var_number_sk and the checksum_sk in the upper table until it aligned well with the lower Module 2 and Module 3. I called the extra column label_4_sk in the Slovak version and label_4_en in English.
At this step, I also remove the footnotes. This step is not critical; when in doubt, leave them be. Removing them in R programmatically would potentially need much exception handling (if the footnotes appear in different locations), so I just do it this way because I have to work in Excel on the alignment of the columns.
Now everything is almost tidy; the most critical information, i.e., where we find the Concerts/performances of the reporting ensemble in Slovakia total in the microdata, is aligned with the labels of every other variable.
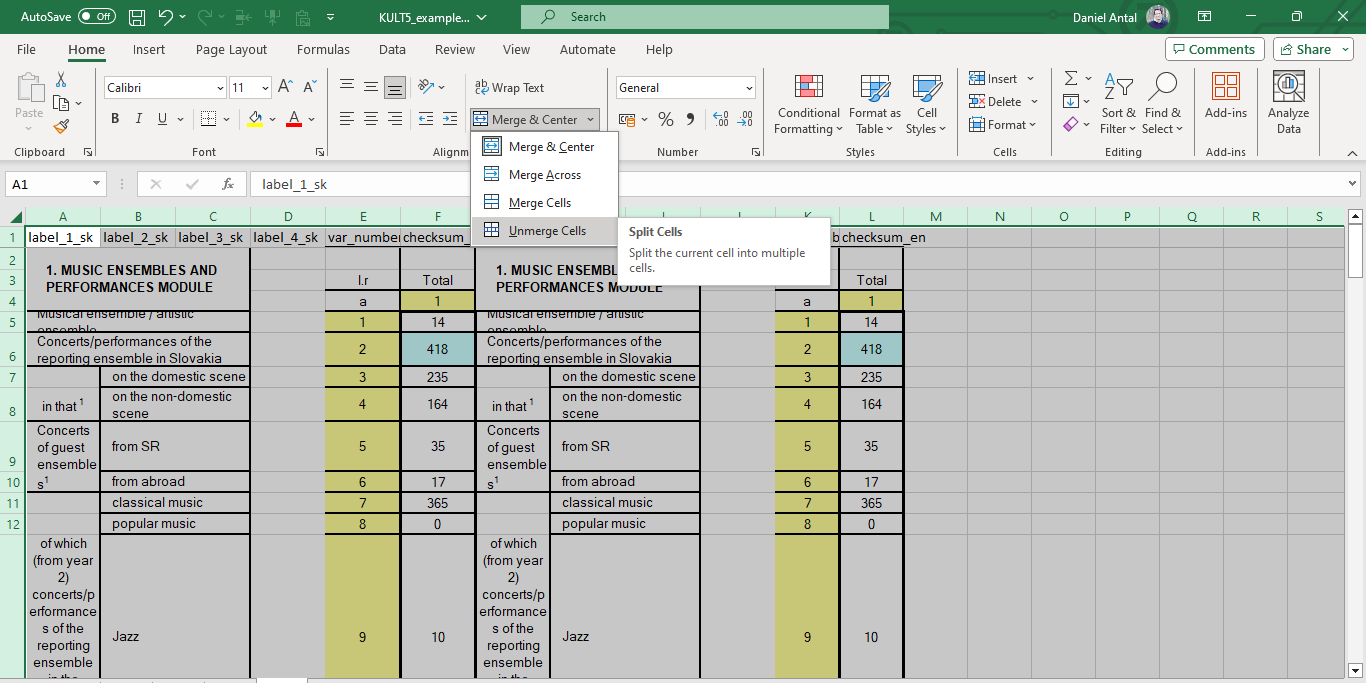
The last step is breaking up merged columns in Excel. Combining columns is a good practice for human readability. It will not work well with a computer-actionable table because the computer does not know intuitively what the merging means. So, I point the mouse to the select all table field (the little triangle. between the A heading for the first column and the 1 row label for the first row), and when the entire sheet is selected, I navigate to unmerge cells and break them up.
As a result, the Excel table is less readable for humans but more understandable for the processing workflow. It is a bit disturbing that the variable labels (i.e., the description of the meaning of the variable) is fragmented into 1, 2, 3, or 4 cells, but that will be an easy fix: in R, I will concatenate them into a single label, for example, adding together elements Concerts/performances of the reporting ensemble in Slovakia total separated by - with on the domestic scene in row 8 of my Excel table (corresponding to KULT05.M1.3, or the 3rd column of Module 1 in the KULT05 microdata.) Because we will work with thousands of labels, this concatenation is better done in R; it would take a very long time in Excel, and it is likely that the administrator of that Excel file would get tired and make a mistake at some point.
Remember that all of this post-processing in R is possible if the rows and columns are well aligned. IfConcerts/performances of the reporting ensemble in Slovakia total are not well aligned with on the domestic scene, then the entire codebook and crosswalk table will be useless.